Python:大量レコードのCSVファイルで特定のカラムの重複を集計、テキストファイルへ出力する
大量レコードのCSVファイルから特定の重複カラムについて確認しないといけない場面があり、Pythonを活用してトライした際の備忘録です。 今回は、結果の出力をテキストファイルへしましたので、そちらを知りたい方は後半をご覧ください。
- 環境
venv Python 3.9.6
- スタート時のディレクトリ
folder └── file.csv
方法
- 今回使用するPythonモジュールをインストール
import pandas as pd import codecs
- 分析したいcsvファイルを読み込む
data = pd.read_csv('file.csv')
- Error 発生、今回のファイルだとデータ型に問題がある
<stdin>:1: DtypeWarning: Columns (3,4,25) have mixed types. Specify dtype option on import or set low_memory=False.
- エラーコードを元に
read_csvのlow_memory引数を False に設定する
data = pd.read_csv('file.csv', low_memory=False)
- DataFrameで変数
dataを扱えるようにする
df = pd.DataFrame(data)
- 今回は
genderカラムの重複データが各何個あるか集計
duplicates = df.pivot_table(index =['gender'], aggfunc = 'size')
- 集計の出力を新たな
new_file.txtファイルへ出力(同名ファイルが既存の場合、上書き)
print(duplicates, file=codecs.open('new_file.txt', 'w', 'utf-8'))
↓作成された集計が出力されたテキストファイル
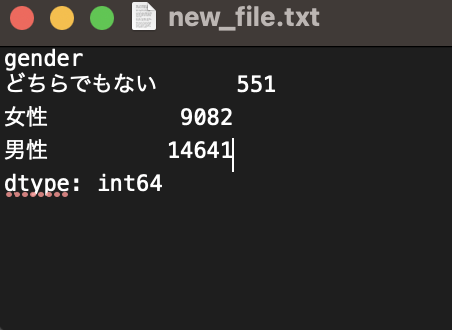
補足
レコード数が不明かつ膨大だったため、あるカラムの集計を上記でする際に、以下、set_option()を活用
データフレームのレコードが途中で省略されることを阻止できます。
pd.set_option("display.max_rows",None)
参考
low_memoryブール値、デフォルトは True ファイルをチャンクで内部的に処理するため、解析中のメモリ使用量が少なくなりますが、型推論が混在する可能性があります。タイプが混在しないようにするには、False を設定するか、dtypeパラメータでタイプを指定します。ファイル全体が単一の DataFrame に読み込まれることに注意してください。